As marketers become more sophisticated in using marketing automation, we increasingly want to take advantage of opportunity information—data about sales and pending deals—to segment nurtures. When you’re creating a nurture for lost opportunities, it can be extremely helpful to know what the opportunity was all about, so you can tailor the content appropriately. An opportunity in Salesforce can have several line items, so it can be challenging to figure out how to put opportunity relationships together in your marketing automation (MA) system.
Why would I want to do this?
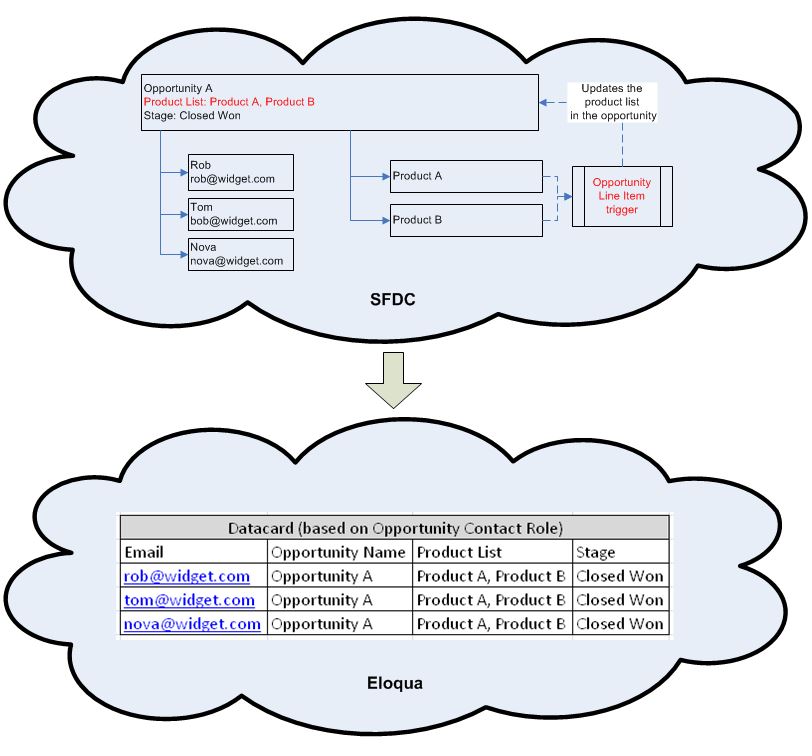
Let’s say you had lost opportunities due to lack of a specific feature, and now that feature has been added in the newest release. So you want to target accounts that have lost opportunities with at least one of the line items having Product X. In that case, the information you need is not in the opportunity records themselves but in the related records like Opportunity Line Items or Assets. In this scenario, it becomes challenging because you’ll find yourself having to connect one too many tables in your fairly flat-structured MA system.
Click to Enlarge
In Eloqua, for example, it’s reasonable to connect Contacts to Accounts and then utilize Datacards to connect to Opportunities, or even connect Contacts directly to Opportunities by way of Opportunity Contact Role records. The challenge is in connecting the Opportunities to another layer of data. Wouldn’t it be “delightful” to be able to see the different product families or asset types related to the opportunity directly ON the opportunity?
Yes, but what is denormalization? For that matter, what’s normalization?
Normalization is the practice of organizing data to reduce dependencies and duplication that can lead to inconsistency. Normalization makes sense in highly transactional databases where there is a lot of writing of data. But when you have a greater need to read data than to write it, denormalization delivers greater efficiency. Denormalization means adding back redundant data, or grouping data, which reduces the need for information to be drawn from several different places and speeds performance.
So, in order to flatten this data and bring it over to the MA, the concept of denormalization comes into play.
How do we handle denormalization in Salesforce?
In Salesforce, one way to accomplish this is by writing a Salesforce Apex trigger. In the example mentioned above, the different Products associated with an Opportunity, we can write an Apex trigger monitoring when an Opportunity Line Item is added, updated, or deleted. When any of these database transactions occur, the Apex trigger will update the Opportunity’s custom field with delimited values of Products related to the Opportunity. With this Product value available directly on the Opportunity records and being synced to your MA, segmentation based on this data becomes relatively easy. (When we’re talking about relational databases, is that a bad pun or a good one?)
Don’t feel confident of your skills in writing an Apex trigger? We’d love to talk with you; to schedule a call, just drop a note to our team.

Augusto Bisda is a DemandGen Solutions Architect with extensive knowledge of application development and best-in-class solutions. As an expert Salesforce developer, Augusto sets a high quality for excellence and continues to exceed that bar on a day-by-day basis.
Leave a Reply