What type of data should be normalized?
Any open text field may be problematic, but data categories that describe the buyer persona or impact business processes are the best candidates for normalization. Translating crazy data into a standardized list gives you the ability to take actions that otherwise would be difficult or impossible to do properly. For example, data such as job title, industry, state, country, or platforms/technologies impact lead scoring and nurture messaging, so accuracy and consistency are vital.
Some common choices for normalization are job titles, locations, and bogus data.
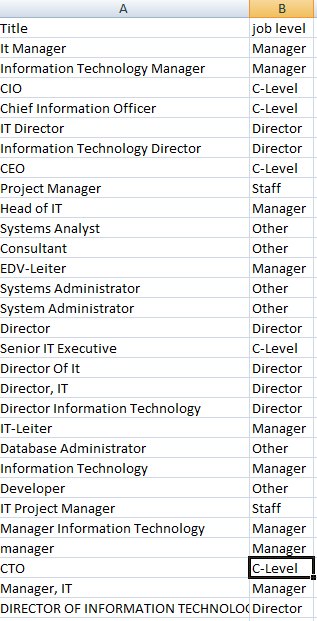
- Job titles—always tricky! Job titles vary greatly among companies and industries, making it nearly impossible to associate a given job title with anything really actionable for segmentation or lead scoring. So standardizing this value can be very useful, and a number of approaches are possible. For example, we used a look-up list approach in a recent engagement. Job title is typically a combination of department/role (engineering, manufacturing, sales, finance) and level (like VP, manager, technician, analyst, associate). In this case, job levels were more meaningful to the customer’s business process, so we implemented a system that translated open-text job titles into job levels using a look-up list.
- Country and state. A finite set of values is most cleanly applied to data points such as country and state. For country, the ISO country code standards are easily applied to translate common entries: for example, “United States of America,” “USA,” and “U.S.A.” all resolve to “US” as a distinct value. For state/territory, the two-letter U.S. abbreviations established by the Postal Service are a common solution.
- Bogus data. Text entries like “Mickey Mouse” and “aaaaaa.com” are maintenance headaches. Using a look-up list of common bad data terms allows you to automatically determine invalid records that have no value.
How does data normalization work?
From a project process standpoint, three steps are key to data normalization:
- Understanding your data and identifying which data fields are important to you
- Knowing the data entry points: forms, list uploads, and other means
- Defining the look-up matrix of possible variations of dirty data and the finite list of data values that are relevant to your business
Step 1: Understanding your data.
Understanding your data is the hardest part: determining the possible permutations of dirty data and what the normalized data should look like. Organizations capture data values in unique ways, and you best know the data points that are most relevant to your business. In a customer engagement, we typically familiarize ourselves with the business situation in order to recommend some starting points, and then evaluate the database set-up for each field, working through to determine what the clean value should look like. For example, a recent client didn’t have a list of job titles to use as a starting point for normalization. So we pulled all the variations of titles in their system, and discovered that it added up to more than 10,000 different values!
Step 2: Knowing the data entry points.
If you’re capturing data from a form, for example, you want to know what data you’re collecting and how you’re collecting it. For instance, at DemandGen we want to know what marketing automation platform prospects use: this data point is important to us for segmentation and qualification. We could ask that question as an open text field on some forms, all forms, or no forms, but understanding where and how this data is collected helps us determine whether normalization is needed. Similarly, knowing that lists that are loaded into our system may collect this data in many different ways (such as from tradeshows, for example) allows us to understand how we could take potential variables of this data and normalize it to the list we want.
Step 3: Defining the normalization matrix.
Click to enlarge
Now it’s time to establish the matrix that maps dirty data to your new standard data values. In the client engagement described above, we took a first stab at identifying job levels for the 10,000 different job title values, and then worked with the client to refine the title-to-level interpretations.
Once you’ve got the matrix, you need a data normalization program in the marketing automation system: essentially, the brain that compares the entry data to the final result. For our clients, we develop this program and then run it against their data: here’s a workflow example (below).
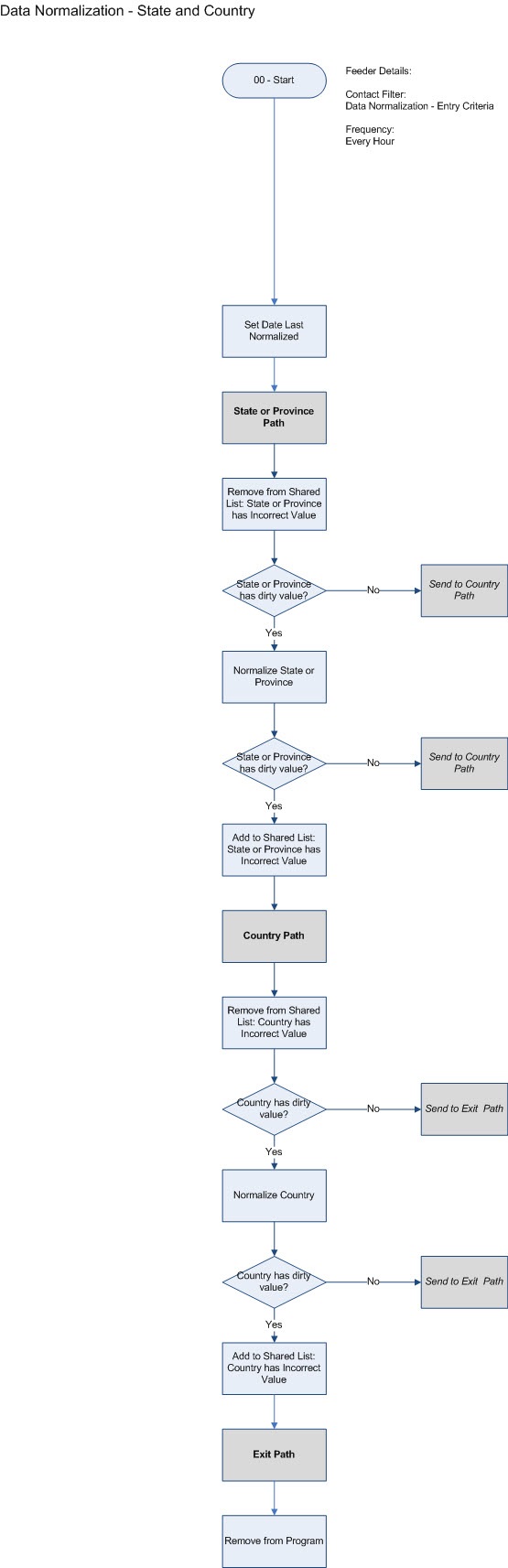
Click to enlarge
For example, if someone submits a title of “VP of Marketing” in an open text field on a form, our program logic evaluates the matrix to see if it finds this value. If it does, the program looks up the corresponding job level in the matrix, and writes that data point to the contact’s record. When the client needs to segment on the job level data, it’s easy to do without necessarily having to ask the end user to specify this data point.
Before you proceed with any business process changes (like changing forms, fields, or routing), evaluate your success: how well did you achieve normalization? Don’t expect perfection: data normalization is an ongoing process for improving data hygiene over time. Individual “hiccups” can be separated out for manual follow-up, but the normalization process reduces significantly the manual effort needed.
Where should data normalization fall in your lead management process?
A lot goes on in your lead management system: putting out campaigns, collecting data through lists and forms, scoring individual leads, passing leads over to the CRM for sales follow-up, adding contacts into nurture campaigns. So any bad data can potentially impact numerous systems and processes. That’s why data normalization should take place at the very beginning of the lead management workflow, and should continually run in the background. That way, you can ensure that every action taken against your data is worthwhile because the data is clean, complete, and meaningful to your business processes.
To wrap it up. . .
Data normalization may seem boring, but data touches so much! If you’re passionate about marketing, you have to care about data accuracy. Remember, data is the fuel that runs your marketing automation engine. . .so don’t let your engine run dry.
 Mali Dvir is Manager of Implementation Services at DemandGen. With more than eight years of marketing automation experience—four of them on staff at Eloqua—and 200+ clients’ worth of knowledge, Mali delivers expertise across a wide spectrum of online marketing practices. Her consulting role often includes marketing best practices and translating requirements to implementation recommendations.
Mali Dvir is Manager of Implementation Services at DemandGen. With more than eight years of marketing automation experience—four of them on staff at Eloqua—and 200+ clients’ worth of knowledge, Mali delivers expertise across a wide spectrum of online marketing practices. Her consulting role often includes marketing best practices and translating requirements to implementation recommendations.
Leave a Reply